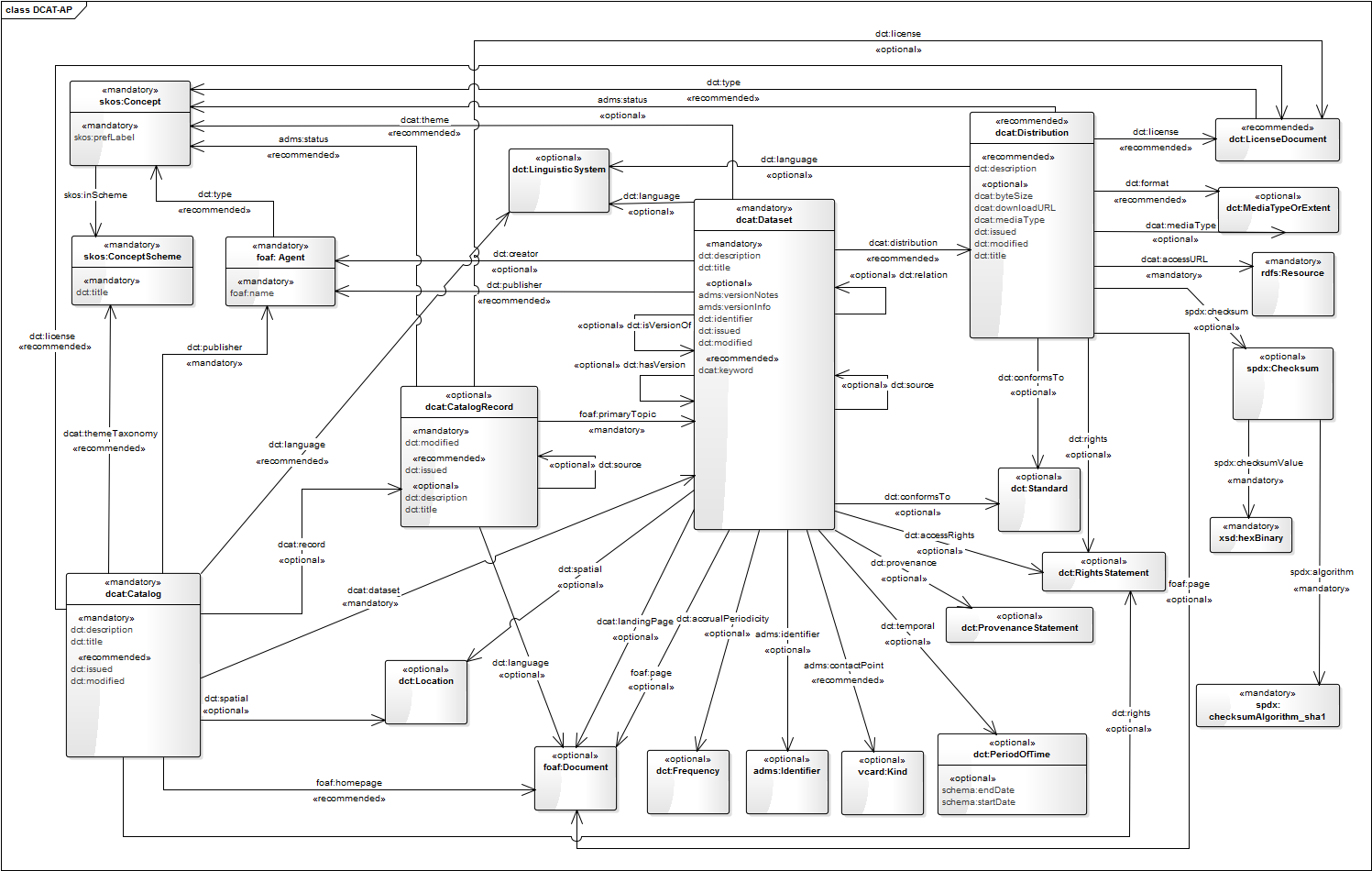
DCAT, which is short for Data Catalog Vocabulary, is a set of terms to describe datasets. Using DCAT all data can be accessed in a uniform way.
DCAT is an RDF vocabulary designed to facilitate interoperability between data catalogs published on the Web. This document defines the schema and provides examples for its use.
This is very abstract, so here is an example to clarify things. A researcher needs information about beetles. Let's say there are three datasets: the beetles in Belgium, the beetles in the Netherlands and cat pictures. The person goes on the web to look for 'beetles' and everything that is related to it. He has to look at the data to see if it is important to his research, but if the researcher finds the data about cats, he won't know if it is irrelevant until he looks at it.
By using DCAT, a computer will be able to do this. The data can be found by a computer if datasets on the internet are standardised. The only thing the researcher has to do is ask the computer fo find all datasets that contain information about beetles.
This project is part of Open Knowledge Belgium. Two students, Stan Callewaert and Sébastien Henau, who participated in open Summer of Code 2015, created this validator. It is funded by the Flemish government and is part of a bigger project that consits of three subprojects of which this validator is one. The intention of this project is to make a validator for DCAT feeds. It shows errors or warnings of classes when respectively mandatory or required properties are missing. These errors and warnings are based on the rules determined by a scheme. The validation can easily be done by manually inserting the feed, uploading a file or inserting a URI.
The user can insert different formats. These formats are RDF:XML, JSON-LD and Turtle. The inserted format will be parsed and serialized to 'Turtle' so that it can be validated. Once the feed is validated the user will receive feedback whether his feed is valid or has errors or warnings. These errors and warnings can be expanded to find more information about its missing or wrong properties. The user can also insert a URI and select the default format 'Automatic' which will detect what format it is, based on the supported formats (Turtle, JSON-LD, RDF:XML), it will parse and serialize it automatically without the user selecting the format.
Many organistions use datasets and try to standardise these by using DCAT. But it is very hard to find the right syntax because there is not much documentation about it. For example: if there is a missing class or property. The computer will have it very difficult to link different datasets together because of the missing attribute. It's because of this we want to make the DCAT validator so that users can see if there feed is valid or not and what elements, classes, attributes or properties have to be adjusted in order for the different datasets to be linked together by computers.
{kind=link}